构建检索增强生成(RAG)系统的关键因素之一:向量嵌入( vector embeddings )。这些元素是基本的技术和转换工具,使 RAG 系统在某些方面能够以类似于人类理解的形式处理语言。
embedding 提供了一种将文本信息转换为数字数据的方法。它允许系统快速搜索和检索最重要的信息以生成响应。这种能力对于提高 LLM 输出的准确性和上下文相关性至关重要。主要为了长文本,kimi 200w 字塞给 LLM 也是这么来的,切割完文本区域后,形成 embedding groups。
在RAG 系统中的 embedding 将数据 embedding 向量数据库以方便检索。
-
搜索相关数据
-
向 LLM 发送相关数据
-
LLM 回答使用发送的数据
什么是 embedding ?
Vector embedding 是机器学习和人工智能中使用的一种强大技术,可将原始数据转换为模型可以轻松处理的数字格式。这里说明下 embedding 跟 LLM 毫无关系,在 LLM 出现之前已经纯在这个技术了。这种转换涉及将数据表示为高维空间中的向量,其中相似的位置得更近,从而实现高效的计算和相似性比较。
Embedding 多种形式
Text embeddings
文本 embedding 是将文本转换为一组向量,其中每个向量代表一个单词或一个句子。Word2Vec、GloVe 和 BERT 等技术通常用于此目的。这些模型的工作原理是根据大型文本语料库中的上下文学习单词的表示。例如,出现在相似上下文中的单词(例如“国王”和“女王”)将具有接近的向量表示。中文需要训练出中文的 embedding 库,不然会导致不准确,或者生僻词无法理解。
Image embeddings
图像 embedding 是将图像转换为数字向量。此类嵌入需要不同类型的嵌入器,在这种情况下,通常使用卷积神经网络(CNN)来生成这些嵌入。图像通过 CNN 的各个层,提取不同抽象级别的特征。输出是一个密集向量,封装了图像的视觉特征,对于图像识别、分类和检索等任务很有用。
Audio embeddings
音频数据也可以转换为向量嵌入。 Mel Frequency Cepstral Coefficients (MFCC) 等技术或 WaveNet 和 DeepSpeech 等深度学习模型用于从原始音频中提取特征。然后,使用这些特征创建表示音频的向量,该向量可用于语音识别、音乐分析和音频分类等应用。
解释:多模态理解后转化成高纬度向量特征
Text embedding 如何工作?
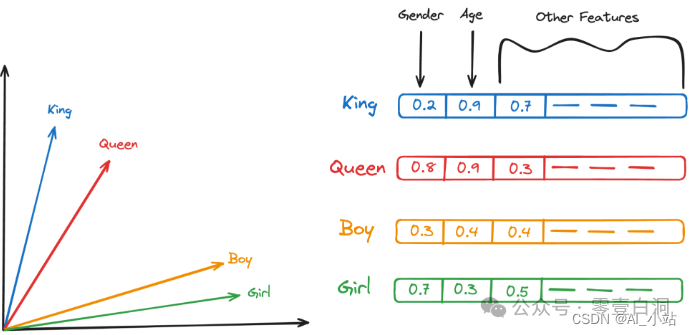
Text embedding 以数字格式表示单词,捕获它们之间共享的语义关系和特征。以下是该过程的工作原理,结合以下示例,其中包括单词“King”、“Queen”、“Boy”和“Girl”。在考虑矢量化时,想象一个多维空间,其中每个维度都可以代表年龄、性别、阶级等特征。在这样的空间中:
- “ King ” 可以表示为坐标上的一个点(男性,皇室)
- “ Queen ”(女性,皇室成员)
- “ Boy ”为(男性,低阶级)
- “ Gril ”为(女性,低阶级)
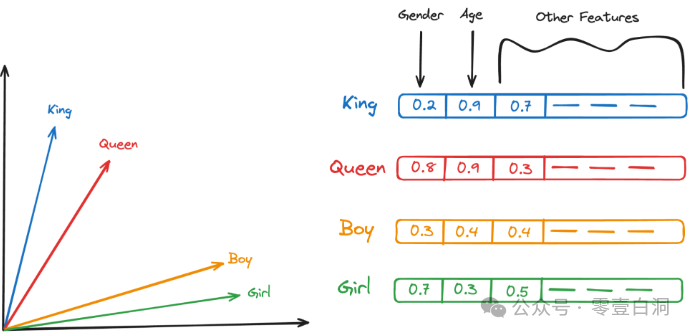
- 性别特征:在矢量空间中,“ King ” 和 “ Boy ”在性别维度上的位置会更接近,反映了他们共同的男性属性。同样,“ Queen ” 和 “ Gril ” 也会因为女性属性而在这个维度上聚集在一起。
- 阶级特征:“ King ” 和 “ Queen ”在皇室维度上彼此接近,反映了他们在皇室中的崇高地位。相比之下,“ Boy ” 和 “ Gril ”由于其一般非皇室身份,在这个维度上可能会距离 “ King ” 和 “ Queen ” 更远
将这些嵌入可以用于各种应用程序,例如:
相似度测量:计算单词之间的距离以找出它们的相似程度(例如,“ King ” 与 “ Queen ” 的距离比 “ King ” 与 “ Boy ” 的距离更近)。解决诸如类比,“国王配对女王,男孩配对什么?”的问题。该模型会发现 “ Girl ” 作为最接近的词向量。
机器翻译和 NLP 任务:使用这些向量来理解情感分析、分类等任务中的文本。embedding 在捕获这种微妙关系方面的有效性使其在自然语言处理中非常有价值,使机器能够以更类似于人类和直观的方式处理文本。Word2Vec、GloVe 以及最近的 BERT 和 GPT 等模型都使用这些原理来创建强大的嵌入。
RAG 系统中的 vector embedding:检索增强生成(RAG)系统是一种先进的 NLP 架构,通过将语言模型与基于检索的信息相结合来增强语言模型的功能。该系统显著提高了语言模型生成的响应的准确性和相关性,特别是在需要特定知识的复杂领域。
矢量数据库与 embedding 结合
在 RAG 系统检索相关数据之前,信息的结构必须使其易于访问和比较。这涉及数据矢量化。所有数据,无论是文本、图像还是任何其他形式,都需要转换为向量。只不过是提取到更高维度,类似 CNN。这意味着数据库中的每个项目都被转换为表示数据的各种特征的高维数值向量。这里科普另一个 RAG graph 的知识(Graph RAG :智能搜索的未来)
矢量数据库创建和存储:然后将这些矢量存储在矢量数据库中,通常使用 FAISS(Facebook AI 相似性搜索)等系统。这些系统允许高效检索接近高维空间中给定查询向量的向量,这对应于检索与查询相似或相关的数据。
RAG系统分三步解释:
第一步查找相关数据,也是查询向量化,当收到查询时,首先使用与创建数据库向量相同的模型或方法将其转换为向量。然后检索,使用查询向量在向量数据库中搜索相似向量。这些向量的相应数据(可以是文本段落、图像等)被认为与查询最相关。
第二步向LLM发送相关数据,检索到的数据通常以语言模型可以轻松使用的方式进行预处理或格式化。这可能涉及总结信息或将其转换为模型可以理解的结构化格式。也就是需要提示词。处理后的相关数据随后被输入大型语言模型 (LLM) 作为附加上下文或输入的一部分。此步骤至关重要,因为它为 LLM 提供了与用户查询直接相关的特定信息。
第三步 LLM 使用发送的数据进行应答,利用检索到的数据提供的上下文,LLM 生成响应。该模型利用了在预训练期间学到的一般知识和检索数据提供的特定信息。最后生成的响应有时会被细化或调整,以确保一致性和相关性。输出将作为初始查询的答案呈现。
RAG 系统的优点
将检索系统与 RAG 设置中的生成模型相集成,不仅可以提供上下文准确的响应,还可以深入了解特定数据,这使得它们在医疗、法律或技术领域等精确信息至关重要的专业领域特别有用。 这种多步骤方法利用了检索系统和生成人工智能的优势,弥补了庞大的数据资源和复杂的语言能力之间的差距,以及专业领域垂直的深度,从而产生内容丰富且与所提出的查询高度相关的输出。
W&B
Weave 是 Weights & Biases 的一款强大工具,旨在简化生产过程中机器学习模型的监控。它提供了一个易于使用的界面,用于跟踪各种指标、可视化数据并实时检查模型性能。通过将 Weave 集成到的 RAG 系统中,增强了在生产过程中监控模型性能的能力。
要使用 Weave,首先使用 weave.init(‘your_project_name’) 对其进行初始化。接下来,将 @weave.op() 装饰器添加到想要跟踪的任何函数中。该装饰器自动记录函数的所有输入和输出,捕获有关其操作的详细信息。然后,用户可以在 Weave 界面中检查这些数据,以便轻松检查函数调用。将在该项目中使用 Weave 来跟踪模型的输入和输出。
构建金融预测的RAG系统
在下面的代码中,将构建我们自己的 RAG 系统。该 RAG 系统将包括 OpenAI LLM、我们从中获取数据的住房数据集、矢量数据库以及 FAISS(用来存储矢量化数据的矢量数据库)。

Step 1: Installing the necessary libraries
# 安装依赖
~pip install langchain langchain-community tiktoken faiss-cpu transformers pandas torch openai
Step 2: Importing the necessary libraries
这些库将包括允许我们构建答案链的 LLMChain、存储矢量化数据的 FAISS 以及作为首选数据嵌入器的 OpenAIEmbeddings。
Step 3: Integrating W&B Weave into our code
# 初始化 weave
weave.init('RAG_System')
Step 4: Loading and processing our dataset
从本地 CSV 文件加载数据集。始终可以使用选择的任何数据集,确保在使用前正确处理数据集。
df = pd.read_csv("/kaggle/input/housing-in-london/housing_in_london_monthly_variables.csv")
# 使用10%的数据
df = df.sample(frac=0.1, random_state=42)
# 将把字段组合成文本字段以便于处理
df['text'] = df.apply(lambda row: f"Date: {row['date']}, Area: {row['area']}, "
f"Average Price: {row['average_price']}, "
f"Code: {row['code']}, Houses Sold: {row['houses_sold']}, "
f"Number of Crimes: {row['no_of_crimes']}, "
f"Borough Flag: {row['borough_flag']}", axis=1)
# 准备好基础数据
texts = df['text'].tolist()
Step 5: Creating and storing our embeddings
# Create embeddings for the texts.
embeddings = OpenAIEmbeddings(api_key=api_key)
vectors = embeddings.embed_documents(texts)
# 创建一个 FAISS 矢量存储并将数据嵌入存储在其中。并且添加了逻辑来缓存向量存储,以避免每次运行时生成新的嵌入:
# Check if the vector store already exists
vector_store_path = "faiss_index"
if os.path.exists(vector_store_path):
# Load the existing vector store
vector_store = FAISS.load_local(vector_store_path, embeddings, allow_dangerous_deserialization=True)
else:
# Create and save the vector store
vectors = embeddings.embed_documents(texts)
vector_store = FAISS.from_texts(texts, embeddings)
vector_store.save_local(vector_store_path)
Step 6: Retrieving our data
定义检索器函数。在本例中,将 K 值定义为 20。这将为给定的每个查询从向量数据库中检索 20 个数据点。
def retrieve(query, k=20):
return vector_store.similarity_search(query, k=k)
# 创建一个prompt_template
prompt_template = PromptTemplate(
input_variables=["context", "question"],
template="""Given the following data from the London housing dataset:
{context}
Please use the provided data to answer the question accurately. Calculate any necessary averages or totals directly from the data provided.
Question: {question}"""
)
Step 7: Testing and evaluating our model
# Initialize the OpenAI LLM, and insert your OpenAI key below.
llm = OpenAI(api_key=api_key)
# Here we will be creating an LLM chain.
llm_chain = LLMChain(prompt=prompt_template, llm=llm)
# We will define a custom function to generate a response using retrieval and LLM chain. Here we leverage W&B Weave so that we can automatically log inputs and outputs to our generate_response function, which allows us to easily monitor how are model is performing in production!
@weave.op()
def generate_response(question):
# Retrieve relevant documents
retrieved_docs = retrieve(question)
context = "\n".join([doc.page_content for doc in retrieved_docs])
# Print the retrieved documents for debugging
print(f"Retrieved documents for question '{question}':")
for i, doc in enumerate(retrieved_docs):
print(f"Document {i+1}:\n{doc.page_content}\n")
# Generate response using LLM chain
response = llm_chain.run(context=context, question=question)
return {"response": response, "context": context}
# Here are sample questions that we will use to test our model.
questions = [
"Using the data retrieved, what was the average price of houses in Westminster in 2019?",
"Using the data retrieved, how many crimes were reported in Hackney in 2018?",
"Using the data retrieved, what is the average price trend in London over the years?",
]
# Get answers to the example questions.
for question in questions:
answer = generate_response(question)
print(f"Q: {question}\nA: {answer}\n")
Weave Logging
以下是模型的结果。由于将 Weave 添加到了generate_response 函数中,这里会自动记录我们的问题、上下文和响应。在 Weave 内部,将看到每个函数调用都有多个单元格,如下所示:
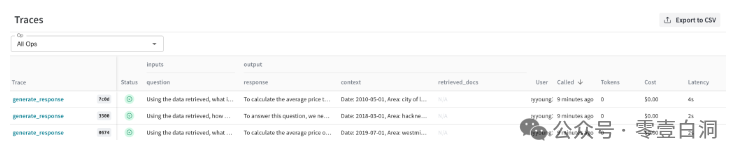
单击任何单元格,并检查有关函数输入和输出的更多详细信息
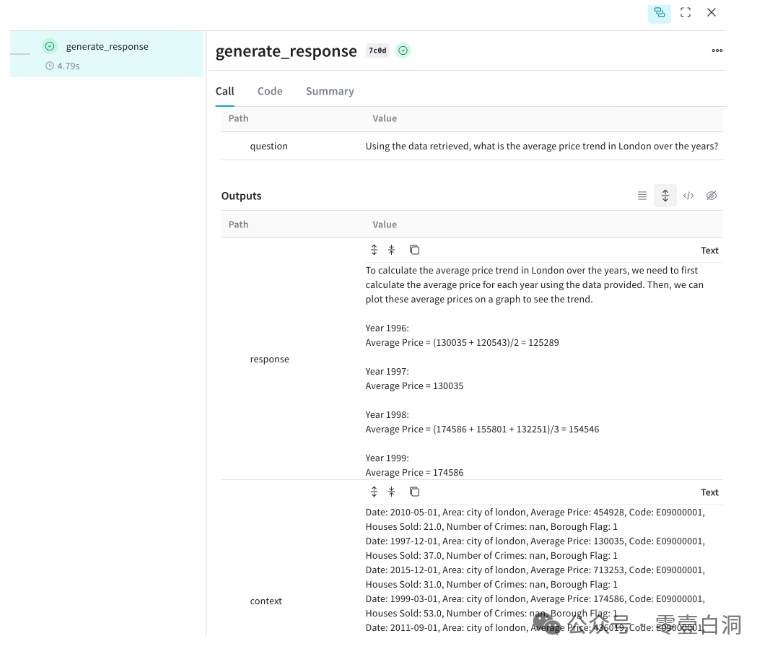
总的来说,Weave 是一个超级简单的工具,可用于在 RAG 系统中记录数据,因为它只需要初始化 Weave,然后添加 @weave.op() 装饰器。例如,可能想要根据以前的生产数据训练新模型,或者可能只是想要一种快速、简单的方法来监控模型的性能。如上所示,上下文是我们的嵌入搜索检索到的信息,而响应是由我们的 LLM 使用检索到的上下文生成的。
结论
通过将各种形式的数据转换为高维向量,嵌入允许 RAG 系统有效地检索和利用相关信息,从而显著提高生成响应的准确性和上下文相关性。矢量嵌入对于提高 RAG 系统的性能至关重要,弥补海量数据资源和复杂的语言能力之间的差距,以提供高度信息化和相关的输出。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。